


Choosing HTTP status codes Series - Part 3
Move along, no resource to see here (truly), HTTP status code 204 vs 403 vs 404 vs 410
By Arnaud Lauret, May 19, 2021
When designing APIs, choosing HTTP status codes is not always that obvious and prone to errors, I hope this post series will help you to avoid common mistakes and choose an adapted one according to the context. This third post answers the following question: given that resource with id 123 actually doesn’t exist in the underlying database, what should be the response to GET /resources/123 when consumer is allowed to access such ressource? 204 No Content, 403 Forbidden, 404 Not Found or 410 Gone?
Choosing HTTP status codes Series
When designing APIs, choosing HTTP status codes is not always that obvious and prone to errors, I hope this post series will help you to avoid common mistakes and choose an adapted one according to the context.<div class="alert alert-info"> I never remember in which RFCs HTTP status codes are defined. To get a quick access to their documentation, I use Erik Wilde’s Web Concepts. </div>Very special thanks to all Twitter people participating to the #choosehttpstatuscode polls and discussions
- 1 - This is not the HTTP method you're looking for, HTTP status code 404 vs 405 vs 501
- 2 - Hands off that resource, HTTP status code 401 vs 403 vs 404
- 3 - Move along, no resource to see here (truly), HTTP status code 204 vs 403 vs 404 vs 410
- 4 - Empty list, HTTP status code 200 vs 204 vs 404
The context
Let’s say your are creating an API for a library, obviously you’ll design a GET /books to search for books and a GET /books/{isbn} to get detailed information about a book.
You did use an International Standard Book Number because such a unique and universally known id is far more convenient than an opaque bookId generated by your implementation.
Indeed using standard/well known values for resource identifiers makes an API more interoperable and usable in other contexts than yours.
Design digression is over, let’s get back to the true topic of this post: choosing an HTTP status code.
A library may not own all books that have been published on earth , end users may also simply mistype an ISBN or books may have been removed from the library.
What should be the response to a GET /books/{not known, totally wrong or not present anymore ISBN}?
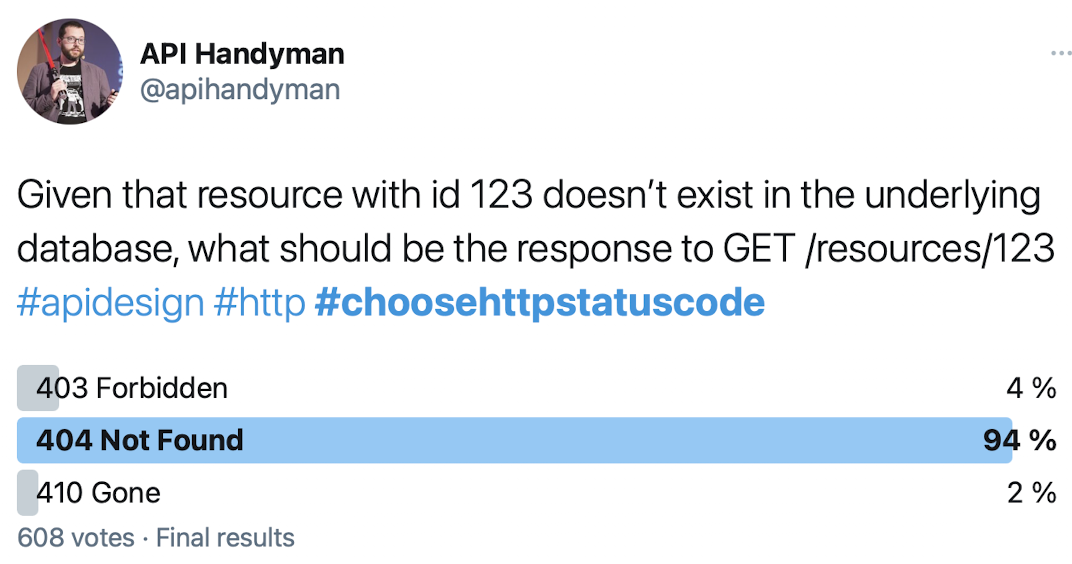
According to my (vague) Twitter poll (which was not explicitly talking about the removed use case), 94% of respondents would return a 404 Not Found, while 4% would return a 403 Forbidden and 2% would return a 410 Gone.
Note also that, in the discussion, some people mentioned returning a 204 No Content.
Let’s see what could be the correct answer(s) according to RFCs.
No brainer, use 404
The 404 (Not Found) status code indicates that the origin server did not find a current representation for the target resource or is not willing to disclose that one exists.
Let’s start with what is the most common and valid response in such a case: 404
This HTTP status code reason Not Found is both obvious and actually means what everybody thinks it means (which is not always the case).
In our case a GET /books/{totally wrong ISBN} must return a 404
And that must be your favorite response when consumer is requesting something that doesn’t exist, not only because RFC 7231 says so, but also because people are used to get that response in such a case.
Being consistent with the rest of the world is a rule of thumb when building APIs (or whatever).
Though people are used to it, there can be some subtleties that requires a more specific HTTP status code when signifying “that doesn’t exist”.
Has existed and can do something about it, you may use 410
The 410 (Gone) status code indicates that access to the target resource is no longer available at the origin server and that this condition is likely to be permanent.
In our case a GET /books/{"book that once has been in library but is no more" ISBN} could return such a status code, especially if the end user is a librarian who deleted a book by mistake.
Digression: A regular library user may get a 404 Not Found for the same request.
That means that your API may return different responses depending on who is the consumer/end/user.
Your database state is not your API data state, the data returned by an API may not be exactly how they actually are in the underlying database (we already have seen that in previous post). It’s not unusual to use a soft delete when removing something from a database and so simply flag it as “deleted” but keeping the data. There are many reasons to do that, regulations like GDPR may force you to do so (though you should move such data in another database) or you may want to propose an “undo” possibility.
A 410 could also be a good response to a request made on an expired temporary URL (that was valid only for a short period of time, that reminds me to write a post about signed URLs).
Whatever the reason of signifying that something actually existed, you may return a 410 Gone if and only if consumers can do something about it (like undoing something or requesting a new temporary URL).
But in that case you should provide information about what they can do about it and how (in response body or at least in documentation).
No scopes, rights or privilege involved, don’t use 403
The 403 (Forbidden) status code indicates that the server understood the request but refuses to authorize it. A server that wishes to make public why the request has been forbidden can describe that reason in the response payload (if any).
In our library use case there are no scopes/privileges/rights involved, a GET /books/{wrong ISBN} will never ever return a 403 Forbidden but a 404 Not Found.
A GET /books/{has existed ISBN} may return a 410 Gone as seen in previous section.
It’s only after that, when trying to undelete the book, maybe with a PUT /books/{"book that once has been in library but is no more" ISBN}, that the response could be a 403 Forbidden if librarian is not allowed to to so.
If privileges/rights are involved when accessing resources (either WHATEVER /books/{isbn} in general or a specific WHATEVER /books/{specific isbn}), a 403 may be returned, you should read Choosing HTTP status codes Part 2 - Hands off that resource, HTTP status code 401 vs 403 vs 404 to learn more about that.
It’s a consumer error, don’t use 204
The 204 (No Content) status code indicates that the server has successfully fulfilled the request and that there is no additional content to send in the response payload body.
Obviously, I didn’t include 204 No Content in the poll because Twitter only allows 3 choices …
Well to be honest, though I often meet people wanting to use it that way, I totally forget it for that poll 😅 (and would probably had propose it instead of 403 Forbidden).
The No Content reason may fool you, but the description is quite clear, it doesn’t mean “there’s nothing for this path” but “these is something for this path but not content to return”.
Also that HTTP status is a 2xx Success class, it is not intended to signify that something went wrong which is the case here, consumer did send a non existing/wrong resource id.
So you should avoid using it in such a case.
