


Surviving my first (recorded) live coding session Series - Part 5
Improving live coding session tuning and rehearsing with VS Code
By Arnaud Lauret, September 1, 2021
Fifth and last post about my first ever (recorded) live coding session given at the Manning API Conference. Thanks to all the work done, I had a good setup, great visual style, titles over VS Code, speaker’s notes and was able to code at light speed. But I was hesitant and not fast enough when presenting, I needed to train myself and fine tune, optimize or remove content to make things smooth and keep in given time frame. And once again VS Code went to the rescue.
Surviving my first (recorded) live coding session Series
I did my first ever (recorded) live coding session at the Manning API conference: Supercharge OpenAPI to efficiently describe APIs (click to what it!). It was about the OpenAPI Specification, how to use it efficiently when designing and documenting API. The idea was to write an OpenAPI Specification document and show the spec basic to advanced features, tips and tricks and use a few tools around all that. This post series aim to share all what I’ve learned preparing this session.
Spoiler alert!
You can get all VS Code stuff explained in this series in my supercharged-openapi github repository. It is the one that I actually used during the session.
- 1 - Setting up everything to record myself coding and talking
- 2 - Preparing session content and realizing it's not working well
- 3 - Slide deck like live coding with titles and speaker's notes using OBS and VS Code
- 4 - Live coding at light speed with VS Code
- 5 - Improving live coding session tuning and rehearsing with VS Code
Training as usual was not easy
It’s not specific to this coding session, but when I prepare a talk there are always parts that needs more training than others. It is quite easy when working on slides to just jump to the first slide of the part I need to work on, and again, and again until satisfied. I can go 1 or 2 slides back if I want. And I can work on parts almost randomly depending on my mood. While training, I can also adapt content to shorten/remove some element because it’s too long.
It was not that easy to do that here. Jump back and forth was complicated and modifying the content also.
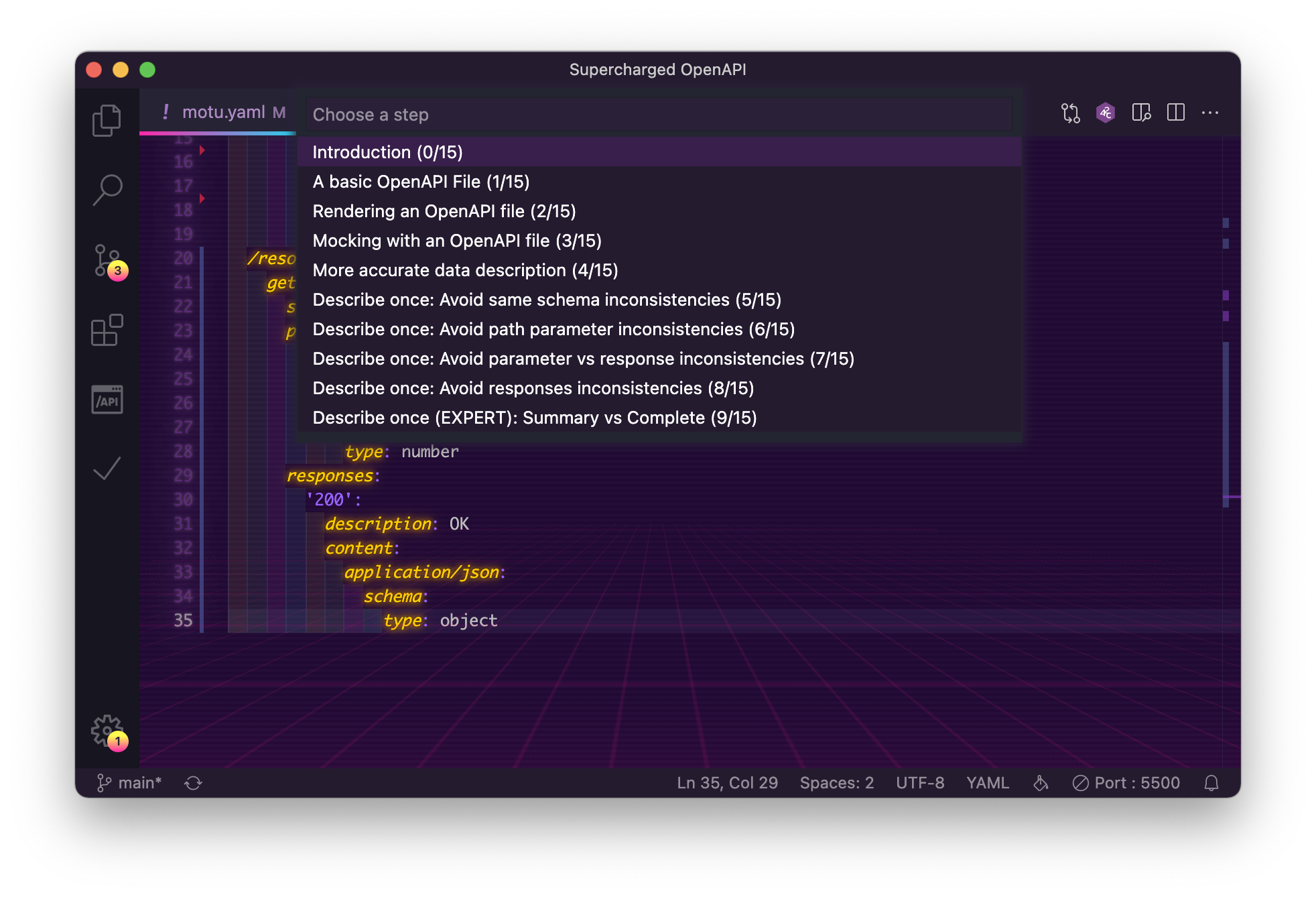
Jumping back and forth to any step
Jumping to any part of the presentation was complicated in the beginning because when I wanted to practice a specific part I had to re-prepare the OpenAPI file to put it in the state needed for this part. If I wanted to go “1 or 2 slides” back I had to carefully remember what to remove in my OpenAPI file.
At first I thought using branches or tagged commits, but based on a previous experience (for my JQ and OpenAPI series) I knew this was not going to work here. Indeed, it’s complicated to do a “replace all” across files in separate branches, while it’s dead simple to do that on multiple files in a folder (even when there are sub folders).
And I already had a good part of the solution: I just had to create a motu.yaml file in each steps/step-X folder.
Thanks to the “Next step” task, the OpenAPI file corresponding to the step was copied to the root folder just like index and todo files.
VS Code handled the motu.yaml file reloading totally seamlessly.
That trick also allowed to magically add code (actual code or comments) when switching to a new step, that was really convenient.
That also ensured that when switching to a new step, the OpenAPI file was in the expected status even if I had to skip something in previous step.
I also added new bash scripts and new tasks to be able to go to previous step and restart. That way I could easily go to the step I wanted to practice. After a while, once content has been stabilized I also added other scripts and tasks and ended with the followings:
| Task | Script triggered | Description |
|---|---|---|
| Go to step | steps/go.sh $step |
Copy steps/step-{$step} content to root level (does nothing if step doesn’t exist). The $step can be either a number or the step’s name coming from the todo.html files, "More accurate data description (4/15)" for instance. The tasks shows the list of available steps (hardcoded in tasks.json file) |
| Next step | steps/next.sh |
Copy steps/step-{current step + 1} content to root level (does nothing if step doesn’t exist) |
| Previous step | steps/previous.sh |
Copy steps/step-{current step - 1} content to root level (does nothing if step doesn’t exist) |
| Reload step | steps/reload.sh |
Copy steps/step-{current step} content to root level (useful to check modifications done on current step) |
| Reset step | steps/reset.sh |
Copy steps/reset content to root level (to restart from the beginning) |
| Clean before commit | steps/clean.sh |
Remove index.css, index.html, todo.html, motu.yaml files from root folder |
I only defined key bindings for Next and Previous step tasks. The “Go to step” is quite convenient but unfortunately the step list is hardcoded and I only had the idea after the recording (I added it so people using the repo could go to the step they want).
Removing stuff was a pain
As I was able to work on each step, I could easily train myself on each step and evaluate the best possible time for each step. And so I came to the conclusion that I was still not fitting into the time frame, though I had an extra 5 minutes granted by conference organizers, saperlipopette! (french polite curse word). Thanks to my list of steps and their timing, I had a better vision of what I should modify and so I:
- Shorten some steps, by for instance starting with a pre-filled basic OpenAPI files or adding snippets
- Removed some steps not bringing interesting information (like spending 30s explaining the various use of the OpenAPI Spec)
- Removed some steps that were kind of duplicating other steps or not bringing interesting information
The modifications were easy to do on my list … but handling the impacts on my various files was a bit laborious. Especially the todo files containing the useful “step X/Y” information. If I was not in a rush I would have redo everything in order to make such modification simpler … But sometimes it is better to leave well enough alone (“the best is the enemy of good” as we say in french), it took me less time to fix all that the ugly way than rethink the entire system.
Recording, celebrating and recovering
And after all that, working weekends and nights (I have a day job and a blog to handle), I was able to do the recording at last, and that went well on second take (the first one was 95% good but I forgot something just in the end… saperlipopette again). I did not really practiced the full session before the actual recording, as I worked more on separated steps, but with more time to practice I should be able to do this session totally live without problem. By the way, final tips: don’t forget to put you phone AND you computer in do not disturb mode in order to avoid unwanted notifications when giving or recording a presentation.
I was really happy when it was at last done. I was quite proud of this very first coding session though it did not looked as expected and I always see some imperfections and possible improvements. Being able to talk without having my word for word speech was a also great achievement.
I was happy but that left me totally exhausted. I felt just like if I had traveled to the other side of earth, spoke and attended at a in person 2 days conference and suffered jet lag. It took me more than a week to recover.
Sharing successes and failures
But all this was worth the cost; I learned a lot, attendees were happy and I hope that this 5 posts series will help others doing coding sessions! I hope also that I was able to show you that behind what may look like total perfection, total mastery, there is practice, simple tools but also failures, doubts, curse words … and magic tricks.
